عندما نستخدم أدوات مثل Skype و QQ لإجراء محادثات صوتية ومرئية مع الأصدقاء بسلاسة ، هل تساءلنا يومًا ما هي التقنيات القوية وراء ذلك؟ ستقدم هذه المقالة مقدمة موجزة عن التقنيات المستخدمة في المكالمات الصوتية عبر الشبكة ، والتي يمكن اعتبارها لمحة عن النمر.
1. النموذج المفاهيمي
عادةً ما تكون المكالمات الصوتية عبر الإنترنت ثنائية الاتجاه ، وهي متماثلة على مستوى النموذج. من أجل البساطة ، يمكننا مناقشة القناة في اتجاه واحد. أحد الطرفين يتحدث والطرف الآخر يسمع الصوت. يبدو الأمر بسيطًا وسريعًا ، لكن العملية الكامنة وراءه معقدة للغاية.
هذا هو النموذج الأساسي الذي يتكون من خمسة روابط مهمة: الاكتساب والتشفير والإرسال وفك التشفير والتشغيل.
(1) جمع الصوت
يشير جمع الصوت إلى جمع البيانات الصوتية من الميكروفون ، أي تحويل عينات الصوت إلى إشارات رقمية. وهو يتضمن عدة معلمات مهمة: تردد أخذ العينات ، وعدد بتات أخذ العينات ، وعدد القنوات.
بكل بساطة: تكرار أخذ العينات هو عدد إجراءات الاستحواذ في ثانية واحدة ؛ عدد بتات أخذ العينات هو طول البيانات التي تم الحصول عليها لكل إجراء اكتساب.
حجم الرتل السمعي يساوي: (تردد أخذ العينات × عدد بتات العينة × عدد القنوات × الوقت)
عادةً ما تكون مدة إطار الاعتيان 10 مللي ثانية ، أي أن كل 10 مللي ثانية من البيانات تشكل إطارًا سمعيًا. بافتراض أن: معدل أخذ العينات هو 16 كيلو بايت ، وعدد بتات العينات هو 16 بت ، وعدد القنوات 1 ، ثم يكون حجم إطار الصوت 10 مللي ثانية: (16000 * 16 * 1 * 0.01) / 8 = 320 بايت. في صيغة الحساب ، 0.01 ثانية ، أي 10 مللي ثانية.
(2) الترميز
بافتراض أننا نرسل إطار الصوت الذي تم تجميعه مباشرة بدون تشفير ، يمكننا حساب متطلبات النطاق الترددي المطلوب. لا يزال المثال أعلاه: 320 * 100 = 32 كيلو بايت / ثانية ، إذا تم تحويلها إلى بت / ثانية ، فسيكون 256 كيلو بايت / ثانية. هذا كثير من استخدام النطاق الترددي. باستخدام أدوات مراقبة حركة مرور الشبكة ، يمكننا أن نجد أنه عند إجراء مكالمات صوتية باستخدام برنامج مراسلة فورية مثل QQ ، تكون حركة المرور 3-5 كيلوبايت / ثانية ، وهو ترتيب من حيث الحجم أصغر من حركة المرور الأصلية. هذا يرجع أساسًا إلى تقنية تشفير الصوت. لذلك ، في تطبيق المكالمات الصوتية الفعلي ، لا غنى عن رابط التشفير هذا. هناك العديد من تقنيات ترميز الكلام الشائعة الاستخدام ، مثل G.729 و iLBC و AAC و SPEEX وما إلى ذلك.
(3) نقل الشبكة
عندما يتم تشفير إطار صوتي ، يمكن إرساله إلى المتصل عبر الشبكة. بالنسبة لتطبيقات الوقت الفعلي مثل المحادثات الصوتية ، يعد زمن الانتقال المنخفض والاستقرار أمرًا مهمًا للغاية ، مما يتطلب من شبكتنا الإرسال بسلاسة تامة.
(4) فك
عندما يتلقى الطرف الآخر الإطار المشفر ، سيقوم بفك تشفيره لاستعادته إلى البيانات التي يمكن تشغيلها مباشرة بواسطة بطاقة الصوت.
(5) تشغيل الصوت
بعد اكتمال فك التشفير ، يمكن إرسال إطار الصوت الذي تم الحصول عليه إلى بطاقة الصوت للتشغيل. المرفقات: يمكنك الرجوع إلى المقدمة وكود المصدر التجريبي وتنزيل SDK لـ MPlayer ، وهو مكون تشغيل صوت
2. الصعوبات والحلول في التطبيقات العملية
إذا كان الاعتماد على التكنولوجيا المذكورة أعلاه فقط يمكن أن يحقق نظام حوار سليم مطبق على شبكة المنطقة الواسعة ، فلا داعي لكتابة هذا المقال. إنه بالتحديد أن العديد من العوامل الواقعية قد أدخلت العديد من التحديات للنموذج المفاهيمي المذكور أعلاه ، مما يجعل تحقيق نظام صوت الشبكة ليس بهذه البساطة ، والذي يتضمن العديد من التقنيات المهنية. بالطبع ، معظم هذه التحديات لديها بالفعل حلول ناضجة. بادئ ذي بدء ، نحتاج إلى تحديد نظام حوار صوتي "ذو تأثير جيد". أعتقد أنه يجب أن يحقق النقاط التالية:
(1) زمن انتقال منخفض. فقط مع زمن انتقال منخفض ، يمكن للطرفين في المكالمة أن يكون لديهما شعور قوي بالوقت الحقيقي. بالطبع ، هذا يعتمد بشكل أساسي على سرعة الشبكة والمسافة بين المواقع المادية للطرفين على المكالمة. من منظور البرمجيات الخالصة ، فإن إمكانية التحسين صغيرة جدًا.
(2) ضوضاء خلفية منخفضة.
(3) الصوت سلس ، دون الشعور بالتوقف أو التوقف.
(4) لا يوجد رد.
أدناه سنتحدث عن التقنيات الإضافية المستخدمة في نظام الحوار الصوتي للشبكة الفعلي واحدًا تلو الآخر.
1. إلغاء الصدى AEC اعتاد الجميع الآن على استخدام وظيفة تشغيل الصوت للكمبيوتر أو الكمبيوتر المحمول مباشرة أثناء الدردشة الصوتية. كما يعلم الجميع ، شكلت هذه العادة الصغيرة تحديًا كبيرًا لتكنولوجيا الصوت. عند استخدام وظيفة مكبر الصوت ، سيتم جمع الصوت الذي يتم تشغيله بواسطة مكبر الصوت بواسطة الميكروفون مرة أخرى وإرساله مرة أخرى إلى الطرف الآخر ، بحيث يمكن للطرف الآخر سماع صدى الصوت الخاص به. لذلك ، في التطبيقات العملية ، فإن وظيفة إلغاء الصدى ضرورية. بعد الحصول على إطار الصوت الذي تم تجميعه ، فإن هذه الفجوة قبل التشفير هي وقت عمل وحدة إلغاء الصدى. المبدأ هو ببساطة أن وحدة إلغاء الصدى تقوم ببعض العمليات الشبيهة بالإلغاء في إطار الصوت المُجمع وفقًا لإطار الصوت الذي تم تشغيله للتو ، وذلك لإزالة الصدى من الإطار المُجمع. هذه العملية معقدة للغاية ، وهي مرتبطة أيضًا بحجم الغرفة التي تتواجد فيها أثناء الدردشة ، وموقعك في الغرفة ، لأن هذه المعلومات تحدد طول انعكاس الموجة الصوتية. يمكن لوحدة إلغاء الصدى الذكية ضبط المعلمات الداخلية ديناميكيًا للتكيف بشكل أفضل مع البيئة الحالية.
2. قمع الضوضاء DENOISE يعتمد منع الضوضاء ، المعروف أيضًا باسم معالجة تقليل الضوضاء ، على خصائص البيانات الصوتية لتحديد جزء ضوضاء الخلفية وتصفيته خارج الإطارات الصوتية. تحتوي العديد من برامج التشفير على هذه الميزة مضمنة.
3. JitterBuffer يتم استخدام المخزن المؤقت للتشويش لحل مشكلة ارتعاش الشبكة. يعني ما يسمى بعدم استقرار الشبكة أن تأخير الشبكة سيكون أكبر وأصغر. في هذه الحالة ، حتى إذا كان المرسل يرسل حزم البيانات بانتظام (على سبيل المثال ، يتم إرسال حزمة كل 100 مللي ثانية) ، لا يمكن للمستقبل تلقي نفس التوقيت. في بعض الأحيان لا يمكن تلقي أي حزمة في دورة ، وفي بعض الأحيان يتم تلقي عدة حزم في دورة. بهذه الطريقة ، يكون الصوت الذي يسمعه المتلقي عبارة عن بطاقة واحدة وبطاقة واحدة. يعمل JitterBuffer بعد وحدة فك الترميز وقبل تشغيل الصوت. أي ، بعد اكتمال فك تشفير الكلام ، يتم وضع الإطار الذي تم فك تشفيره في JitterBuffer ، وعندما يصل استدعاء إعادة تشغيل بطاقة الصوت ، يتم استرداد أقدم إطار من JitterBuffer للتشغيل. يعتمد عمق المخزن المؤقت لـ JitterBuffer على درجة ارتعاش الشبكة. كلما زاد تذبذب الشبكة ، زاد عمق المخزن المؤقت وزاد التأخير في تشغيل الصوت. لذلك ، يستخدم JitterBuffer تأخيرًا أعلى في مقابل تشغيل الصوت السلس ، لأنه مقارنة ببطاقة واحدة بطاقة واحدة ، وتأخير أكبر قليلاً ولكن تأثير أكثر سلاسة ، فإن تجربته الشخصية أفضل. بالطبع ، عمق المخزن المؤقت لـ JitterBuffer ليس ثابتًا ، ولكن يتم تعديله ديناميكيًا وفقًا للتغيرات في درجة اهتزاز الشبكة. عندما تتم استعادة الشبكة لتكون سلسة للغاية وبدون عوائق ، سيكون عمق المخزن المؤقت صغيرًا جدًا ، بحيث تكون الزيادة في تأخير التشغيل بسبب JitterBuffer ضئيلة للغاية.
4. كشف كتم الصوت في أيه دي في أي محادثة صوتية ، إذا كان أحد الأطراف لا يتحدث ، فلن يتم إنشاء أي حركة مرور. يستخدم الكشف عن كتم الصوت لهذا الغرض. عادةً ما يتم أيضًا دمج اكتشاف كتم الصوت في وحدة الترميز. يمكن لخوارزمية الكشف الصامت جنبًا إلى جنب مع خوارزمية قمع الضوضاء السابقة تحديد ما إذا كان هناك إدخال صوتي حاليًا. إذا لم يكن هناك إدخال صوتي ، فيمكنه تشفير وإخراج إطار مشفر خاص (على سبيل المثال ، الطول هو 0). خاصة في مؤتمر الفيديو متعدد الأشخاص ، عادة ما يتحدث شخص واحد فقط. في هذه الحالة ، لا يزال استخدام تقنية الكشف الصامت لتوفير النطاق الترددي كبيرًا للغاية.
5. خلط الخوارزمية في الدردشة الصوتية متعددة الأشخاص ، نحتاج إلى تشغيل البيانات الصوتية من عدة أشخاص في نفس الوقت ، وتقوم بطاقة الصوت بتشغيل مخزن مؤقت واحد فقط. لذلك ، نحتاج إلى مزج عدة أصوات في صوت واحد. هذا ما تفعله خوارزمية الخلط. حتى إذا تمكنت من العثور على طريقة لتجاوز الاختلاط والسماح بتشغيل أصوات متعددة في نفس الوقت ، فلغرض إلغاء الصدى ، يجب مزجها في تشغيل واحد ، وإلا فإن إلغاء الصدى يمكنه فقط القضاء على بعض الأصوات المتعددة في عظم. طوال الطريق. يمكن أن يتم الخلط من جانب العميل أو على جانب الخادم (والذي يمكن أن يوفر عرض النطاق الترددي المصب). إذا تم استخدام قنوات P2P ، فلا يمكن إجراء الخلط إلا من جانب العميل. إذا كان الاختلاط على العميل ، فعادة ما يكون الخلط هو الرابط الأخير قبل اللعب. هذه المقالة هي ملخص تقريبي لتجربتنا في تنفيذ الجزء الصوتي من OMCS. هنا ، قمنا للتو بعمل وصف بسيط لكل رابط في الشكل ، ويمكن كتابة أي واحد منهم في ورقة طويلة أو حتى كتاب. لذلك ، هذه المقالة هي فقط لتقديم خريطة تمهيدية لأولئك الجدد في تطوير نظام صوت الشبكة ، وإعطاء بعض القرائن.



|
|
|
|
مدى (طويل) غطاء الارسال؟
مجموعة انتقال يعتمد على عوامل كثيرة. ويستند المسافة الحقيقية على هوائي تركيب ارتفاع، كسب الهوائي، وذلك باستخدام بيئة مثل بناء وغيرها من العوائق، حساسية المتلقي، وهوائي جهاز الاستقبال. تركيب هوائي أكثر عالية واستخدام في الريف، وستكون المسافة أكثر من ذلك بكثير بكثير.
مثال 5W وزير الخارجية الارسال استخدام في المدينة ومسقط:
لدي العملاء استخدام وزير الخارجية الارسال 5W الولايات المتحدة الأمريكية مع هوائي سباق الجائزة الكبرى في مسقط رأسه، وكان اختباره مع سيارة، من تغطية 10km (6.21mile).
أنا اختبار زير الخارجية الارسال 5W مع هوائي سباق الجائزة الكبرى في مسقط رأسي، وتغطي حوالي 2km (1.24mile).
أنا اختبار زير الخارجية الارسال 5W مع هوائي سباق الجائزة الكبرى في مدينة قوانغتشو، وتغطي حوالي 300meter فقط (984ft).
وفيما يلي مجموعة التقريبي لمختلف أجهزة الإرسال FM السلطة. (هذه المجموعة هي قطر)
0.1W ~ 5W وزير الخارجية الارسال: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W وزير الخارجية الارسال: 3KM ~ 10KM
80W ~ 500W وزير الخارجية الارسال: 10KM ~ 30KM
500W ~ 1000W وزير الخارجية الارسال: 30KM ~ 50KM
1KW ~ 2KW وزير الخارجية الارسال: 50KM ~ 100KM
2KW ~ 5KW وزير الخارجية الارسال: 100KM ~ 150KM
5KW ~ 10KW وزير الخارجية الارسال: 150KM ~ 200KM
كيفية الاتصال بنا للحصول على الارسال؟
اتصل بي + 8618078869184 أو
راسلني [البريد الإلكتروني محمي]
1.How الآن تريد تغطية في قطر؟
2.How طويل القامة منكم برج؟
3.Where هي من أنت؟
وسنقدم لكم المزيد من النصائح المهنية.
من نحن
FMUSER.ORG هي شركة تكامل النظام التي تركز على معدات البث / الاستوديوهات الصوتية لنقل الفيديو / الاستوديو اللاسلكي ومعالجة البيانات. نحن نقدم كل شيء من المشورة والاستشارات من خلال تكامل الرف إلى التركيب والتكليف والتدريب.
نحن نقدم جهاز إرسال FM ، جهاز إرسال تلفزيون تناظري ، جهاز إرسال تلفزيون رقمي ، جهاز إرسال VHF UHF ، هوائيات ، موصلات كبل متحد المحور ، STL ، على معالجة الهواء ، منتجات إذاعية للاستوديو ، مراقبة إشارات RF ، وحدات ترميز RDS ، معالجات الصوت ووحدات التحكم في الموقع البعيد ، منتجات IPTV ، تشفير / فك تشفير الفيديو / الصوت ، مصممة لتلبية احتياجات كل من شبكات البث الدولية الكبيرة والمحطات الخاصة الصغيرة على حد سواء.
يحتوي حلنا على محطة راديو FM / محطة تلفزيون تناظرية / محطة تلفزيون رقمية / معدات استوديو الصوت والفيديو / رابط مرسل الاستوديو / نظام القياس عن بعد المرسل / نظام تلفزيون الفندق / البث المباشر IPTV / البث المباشر / البث المباشر / مؤتمر الفيديو / نظام البث CATV.
نحن نستخدم منتجات التكنولوجيا المتقدمة لجميع الأنظمة ، لأننا نعرف أن الموثوقية العالية والأداء العالي مهمان للغاية للنظام والحل. في الوقت نفسه ، علينا أيضًا التأكد من نظام منتجاتنا بسعر معقول جدًا.
لدينا عملاء من المذيعين العامين والتجاريين ومشغلي الاتصالات والهيئات التنظيمية ، كما نقدم الحلول والمنتجات لمئات من المذيعين الأصغر والمحليين والمجتمعين.
FMUSER.ORG تصدر منذ أكثر من 15 عامًا ولديها عملاء في جميع أنحاء العالم. مع 13 عامًا من الخبرة في هذا المجال ، لدينا فريق محترف لحل جميع أنواع مشاكل العملاء. لقد كرسنا جهودنا لتوفير أسعار معقولة للغاية للمنتجات والخدمات المهنية. تواصل بالبريد الاكتروني : [البريد الإلكتروني محمي]
مصنعنا

لدينا تحديث من المصنع. انكم مدعوون الى زيارة المصنع عندما جئت الى الصين.

في الوقت الحاضر، وهناك بالفعل الزبائن 1095 في جميع أنحاء العالم بزيارة مكتبنا قوانغتشو تيانخه. إذا كنت تأتي إلى الصين، انكم مدعوون الى زيارة الولايات المتحدة.
في معرض

هذا هو مشاركتنا في المصادر العالمية 2012 معرض هونغ كونغ للإلكترونيات . العملاء من جميع أنحاء العالم لدينا أخيرا فرصة للحصول على معا.
أين هو FMUSER؟
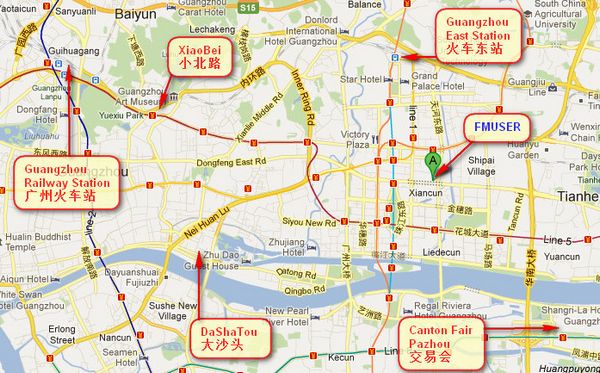
يمكنك البحث عن هذه الأرقام " 23.127460034623816,113.33224654197693 "في خريطة جوجل ، ثم يمكنك العثور على مكتبنا fmuser.
مكتب FMUSER قوانغتشو في حي تيانخه الذي هو مركز كانتون . جدا قرب إلى معرض كانتون , محطة سكة حديد قوانغتشو, الطريق xiaobei وdashatou ، تحتاج فقط 10 دقيقة إذا أخذ سيارة اجره . نرحب الأصدقاء في جميع أنحاء العالم لزيارة والتفاوض.
الاتصال: السماء الزرقاء
الهاتف المحمول: + 8618078869184
ال WhatsApp: + 8618078869184
Wechat: + 8618078869184
البريد الإلكتروني: [البريد الإلكتروني محمي]
QQ: 727926717
سكايب: sky198710021
العنوان: غرفة No.305 HuiLan بناء No.273 Huanpu طريق قوانغتشو الصين الرمز البريدي: 510620
|
|
|
|
الإنجليزية: نحن نقبل جميع المدفوعات ، مثل PayPal و Credit Card و Western Union و Alipay و Money Bookers و T / T و LC و DP و DA و OA و Payoneer ، إذا كان لديك أي سؤال ، فيرجى الاتصال بي [البريد الإلكتروني محمي] أو WhatsApp + 8618078869184
-
باي بال.  www.paypal.com www.paypal.com
ننصحك باستخدام باي بال لشراء سلع لدينا، وباي بال هو وسيلة آمنة لشراء على شبكة الانترنت.
كل من لدينا صفحة قائمة البند أسفل على رأس ديك شعار باي بال للدفع.
بطاقة ائتمان.إذا لم يكن لديك باي بال، ولكن لديك بطاقة الائتمان، يمكنك أيضا النقر فوق الزر باي بال الأصفر لدفع مع بطاقة الائتمان الخاصة بك.
-------------------------------------------------- -------------------
ولكن إذا كان لديك لا بطاقة الائتمان وليس لديك حساب باي بال أو يصعب حصلت على تعاطيه باي بال، يمكنك استخدام ما يلي:
الاتحاد الغربي.  www.westernunion.com www.westernunion.com
الدفع عن طريق ويسترن يونيون لي:
الاسم الأول / الاسم المعطى: Yingfeng
اسم العائلة / اللقب / اسم العائلة: Zhang
الاسم الكامل: Yingfeng Zhang
الدولة: الصين
المدينة: قوانغتشو
|
-------------------------------------------------- -------------------
T / T. ادفع عن طريق تي / تي (حوالة مصرفية / نقل البرقية / حوالة مصرفية)
معلومات البنك الأول (حساب الشركة):
SWIFT BIC: BKCHHKHHXXX
اسم البنك: بنك الصين (هونج كونج) المحدودة ، هونج كونج
عنوان البنك: برج بنك الصين ، 1 GARDEN ROAD ، CENTRAL ، هونج كونج
رمز البنك: 012
اسم الحساب: FMUSER INTERNATIONAL GROUP LIMITED
الحساب لا. : 012-676-2-007855-0
-------------------------------------------------- -------------------
معلومات البنك الثانية (حساب الشركة):
المستفيد: Fmuser International Group Inc
رقم الحساب: شنومكس
بنك المستفيد: بنك التعمير الصيني فرع قوانغدونغ
كود السويفت: PCBCCNBJGDX
العنوان: رقم 553 طريق تيانخه ، قوانغتشو ، قوانغدونغ ، مقاطعة تيانخه ، الصين
** ملاحظة: عند تحويل الأموال إلى حسابنا المصرفي ، يرجى عدم كتابة أي شيء في منطقة الملاحظات ، وإلا فلن نتمكن من استلام الدفعة بسبب سياسة الحكومة الخاصة بأعمال التجارة الدولية.
|
|
|
|
* سيتم إرسالها في 1-2 أيام العمل عند دفع واضح.
* ونحن سوف إرساله إلى عنوانك. إذا كنت ترغب في تغيير عنوان، يرجى ارسال العنوان الصحيح ورقم الهاتف على البريد الإلكتروني الخاص بي [البريد الإلكتروني محمي]
* إذا كان الحزم هو أقل 2kg، فإننا سوف يتم شحنها عن طريق البريد الجوي، وسوف يستغرق حوالي 15-25days إلى يدك.
إذا كانت الحزمة هي أكثر من 2kg، ونحن سوف السفينة عبر نظم الإدارة البيئية، دي إتش إل، يو بي إس، فيديكس اكسبريس وسرعة التسليم، وسوف يستغرق حوالي 7 ~ 15days إلى يدك.
إذا كان أكثر من حزمة و100kg، ونحن سوف ترسل عبر DHL أو الشحن الجوي. وسوف يستغرق حوالي 3 ~ 7days إلى يدك.
كل الحزم هي شكل الصين قوانغتشو.
* سيتم إرسال الحزمة ك "هدية" و declear بأقل قدر ممكن ، لا يحتاج المشتري لدفع "الضرائب".
* بعد السفينة، ونحن سوف نرسل لك رسالة بالبريد الإلكتروني ويعطيك رقم تتبع.
|
|
|
للضمان.
اتصل بنا - >> إعادة العنصر إلينا - >> استلام وإرسال بديل آخر.
الاسم: ليو شياو شيا
العنوان: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu قوانغتشو الصين.
الرمز البريدي: 510620
موبايل: 8618078869184
يرجى العودة إلى هذا العنوان وكتابة عنوان بريدك باي بال، واسم، مشكلة على المذكرة: |
|













